
Ulissi and Facebook AI create world’s largest catalysis dataset
Zack Ulissi and Facebook AI Research (FAIR) have created the Open Catalyst Project, the largest dataset of its kind, to accelerate the discovery of new catalysts for use in renewable energy storage.
For decades, the push toward renewable energy sources like solar and wind has necessitated the development of countless technologies. From generation techniques, to power grid infrastructure and storage methods, renewable power development requires innovation from all angles. Today, thanks to the tireless work of researchers and engineers all over the world, methods for generating renewable energy have come a long way. But there are still major barriers to the full implementation of renewables into the power grid.
Now, Zack Ulissi has teamed up with Facebook AI Research (FAIR) to break down one of these barriers. Combining the expertise in machine learning, dataset development, and computing power of FAIR with Ulissi’s years of prior research using machine learning techniques for novel catalyst discovery, the team is empowering researchers around the world to join in the effort through the Open Catalyst Project, an open effort to produce datasets and models designed to help researchers discover new catalysts for renewable energy storage.
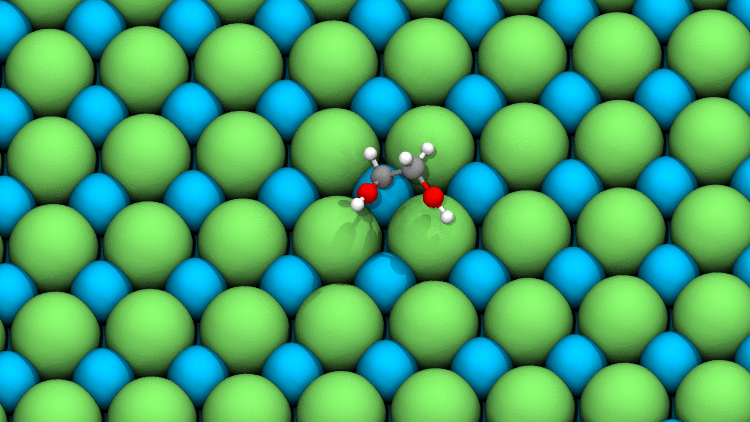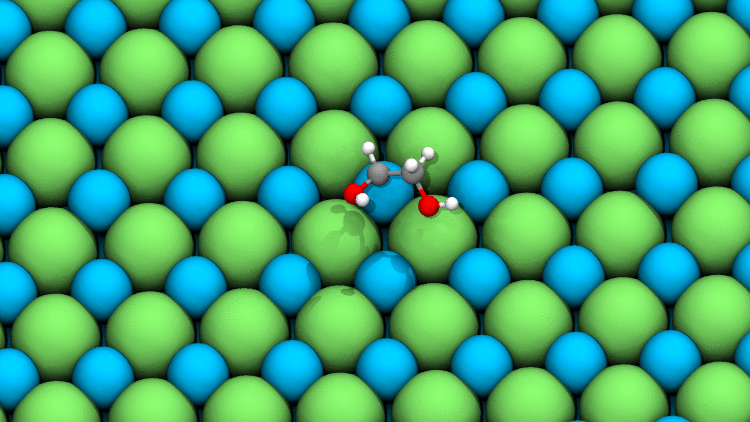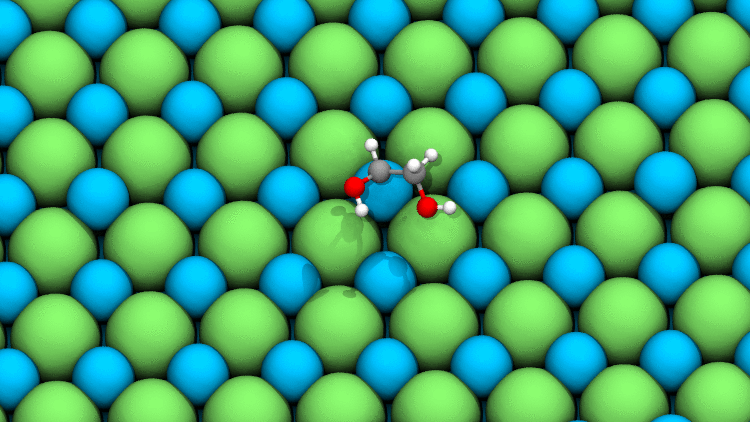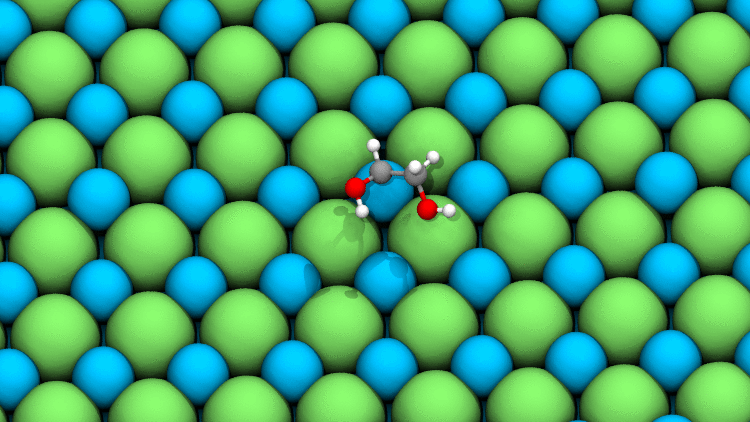
Source: Javier Heras Domingo
This simulation, magnified 108 times, models a typical relaxation between an adsorbate (in color) and a catalyst’s surface. While it looks simple, current DFT methods take hours or even days to calculate all the quantum mechanical forces interacting at this level.
“The adoption of renewable energy sources into the national power grid will require us to answer many questions and solve many problems, such as the problem of intermittency,” says Ulissi, an assistant professor of chemical engineering. “As wind and solar can’t provide constant energy due to the variable nature of their generation, we have to figure out how to store that energy for later use. One of the most promising ways we can do this is by converting that energy into other fuels, like hydrogen or ethanol, through chemical means. But doing so requires highly efficient, effective catalysts to do that chemical conversion—and the discovery and creation of these new catalysis comes with a whole host of its own problems.”
Current methods for converting renewable energy into other fuels requires catalysts that are often incredibly expensive and fairly inefficient, such as platinum. In order to reduce the cost and increase the efficiency of these processes, new catalysts will have to be discovered and implemented. But discovering new catalysts is an arduous and costly undertaking. Catalytic surfaces are made using a combination of several elements known to be effective for these purposes. There are 55 of these elements in the current dataset alone, with nearly 10,000 possible combinations. Add to that the fact that different ratios and configurations of these elements also have an effect, and the possibilities expand into the billions.
The Open Catalyst Project was created to facilitate the rapid exploration of all these billions of possibilities. As the first step in the project, Ulissi, along with Facebook AI research scientist Larry Zitnick and others at FAIR, have created the Open Catalyst 2020 (OC20) dataset, an open source database containing molecular data on more than 1.3 million electrocatalyst relaxations across chemistry and catalysts—the largest dataset of its kind in the world. It’s essentially a catalogue of data on molecules known to be important for renewable energy applications, which will allow machine learning algorithms to quickly test millions of possible combinations, and eventually discover more efficient and inexpensive electrocatalysts.
This project represents a turning point in the adoption of AI in the catalysis community.
Zack Ulissi, Assistant Professor, Chemical Engineering
“This project represents a in the adoption of AI in the catalysis community,” says Ulissi. “It will enable approaches to electrocatalyst discovery across a much broader set of new materials and chemistry. This new collaboration between the machine learning community and catalysis researchers ensures that models built on the OC20 data set will address the most common day-to-day challenges in catalysis.”
While Ulissi has been working for many years on the development of unique machine learning algorithms to help accelerate the field of electrocatalysis, the Open Catalyst Project represents the largest effort to date to mobilize a global effort to move the field of catalysis forward. The hope is that as more researchers begin to utilize the dataset for their own electrocatalysis research, the more quickly the research community as a whole will be able to find solutions that will usher in the widespread adoption of renewable energy sources. Additionally, further use will lead to the continued refinement of the data and resultant modeling tools. For instance, while generating calculations for the OC20 data set currently take anywhere between 12 hours and three days to execute, the ultimate goal is to accelerate the process until they take mere seconds.
“We hope that the Open Catalyst Project and release of the accompanying data set and models will inspire researchers in the broader community, whether interested primarily in AI or catalysis,” the team writes. “This problem presents an interesting opportunity for AI research, both because of the complexity of the systems involved and the accuracy required. And for catalysis researchers, we hope the Open Catalyst Dataset helps jumpstart efforts that were previously hindered by lack of compute.”
To read the full description of the project and its uses, check out the blog post over on Facebook AI’s website.