
Accelerating electrocatalyst discovery
Chemical engineering researchers have developed a machine learning system to search through millions of intermetallics to discover new materials for electrocatalysis.
Researchers are paving the way to total reliance on renewable energy as they study both large- and small-scale ways to replace fossil fuels. One promising avenue is converting simple chemicals into valuable ones using renewable electricity, including processes such as carbon dioxide reduction or water splitting. But to scale these processes up for widespread use, we need to discover new electrocatalysts—substances that increase the rate of an electrochemical reaction that occurs on an electrode surface. To do so, researchers at Carnegie Mellon University are looking to new methods to accelerate the discovery process: machine learning.
Zack Ulissi, an assistant professor of chemical engineering (ChemE), and his group are using machine learning to guide electrocatalyst discovery. By hand, researchers spend hours doing routine calculations on materials that may not end up working. Ulissi’s team has created a system that automates these routine calculations, explores a large search space, and suggests new alloys that have promising properties for electrocatalysis.
“This allows us to spend our time asking science questions, like, ‘How do you predict the properties of something,’ ‘What is the thermodynamic model,’ ‘What is the model of the system,’ or ‘How do you represent the system?’” said Ulissi.
What we’ve built is a smart machine, but our goal isn’t really a smart machine. Our goal is to create a machine that gets us data.
Kevin Tran, Ph.D. student, Chemical Engineering, Carnegie Mellon University
The researchers tested their method on the discovery of intermetallics that could make good electrocatalysts for carbon dioxide reduction and hydrogen evolution—two very complex reactions. A good electrocatalyst is inexpensive, selective, active, efficient, and stable. Many electrocatalysts are made from a class of metals called intermetallics, that when put together have a defined crystal structure. With a machine learning system, it can quickly screen combinations of intermetallics for one or more properties associated with a good electrocatalysts.
Ulissi and Kevin Tran, a ChemE Ph.D. student, have a system of scripts that every night searches a database of the millions of adsorption sites on thousands of intermetallics, or where another element could adhere. Based on that search, the system builds a machine learning model to predict what site it should run calculations on over the next day. It then runs the calculations, which reveal more about the properties of each intermetallic site, and the results are stored in a database and used to retrain the model. Then the loop repeats itself, each time finding better and more interesting materials. In this way, it discounts any materials that wouldn’t make good catalysts, but gives the researcher confidence that the materials the system suggests will not lead to a dead end.
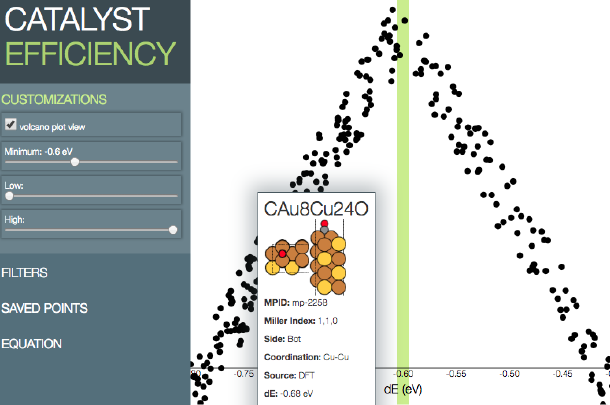
Source: Zack Ulissi
A web interface that displays their electrocatalyst predictions, built by a CMU undergraduate computing class.
“What we’ve built is a smart machine, but our goal isn’t really a smart machine,” said Tran, a co-author on the study. “Our goal is to create a machine that gets us data. So we really use the machine as a farmer, to gather data intelligently.”
While a human could study roughly 10 to 20 new energies a week, the machine can study hundreds per day. Prior to the automated system, researchers would have to narrow the space down to one class of materials and work in that space. Now, they can take a more holistic approach.
Through this study, published in Nature Catalysis, the researchers have a list of materials and intermetallic combinations that experimentalists should try, both for hydrogen evolution and carbon dioxide reduction. The experiments will then determine what will make good electrocatalysts for the large scale.
“I don't think people had done it this way before.” said Ulissi. “At this point we are just narrowing down what experimentalists should focus on. We were able to show that the space is larger than people thought. We found interesting ideas—like if you take two things that are too weak they may actually make something stronger. We had no idea if we were going to find outcomes like that or not.”