
Taking a closer look at steel using computer vision
Inclusions are microscopic particles within steel that have a big impact on its properties and performance. Steelmakers need to analyze them for quality control, and CMU engineers think they can improve the process using computer vision and machine learning.
A version of this story first appeared in Industrial Heating.
What are inclusions?
Inclusions are unavoidable by-products of steel-making. These microscopic particles, arising from different chemical reactions and processes, can vary widely in size, shape, and composition, and have important effects on the material properties of steel. Inclusions have been a focus of industry for more than a century, and remain so in both production settings as well as academic research.
“Inclusions are these little particles floating around in the steel that are always there,” said Bryan Webler, a professor of materials science & engineering (MSE). Solid-phase inclusions can clump together to clog nozzles and other flow control systems that mediate the flow of liquid steel. Some inclusion chemistries reduce ductility, resistance to fatigue, or overall toughness in steels. “They affect the final performance of the steel, which is why we care about them so much.”
Webler and MSE colleague Liz Holm have turned to computer vision and machine learning techniques to study steel inclusions, hoping to make characterizing the microscopic particles faster and less expensive. They shared their initial findings at the 2019 conference of the Association for Iron & Steel Technology.
Inclusion analysis: current practices
Inclusion analysis typically relies on two inputs: images from scanning electron microscopy (SEM), which are analyzed to give information on size, shape, and location, and energy-dispersive spectroscopy (EDS) to identify chemical composition. In production settings, it takes a trained metallurgist a few hours to characterize the inclusions from a sample of steel.
Decreasing that turnaround time, however, could give steelmaking operations tighter control on product quality and raw materials usage. Consider calcium treatments, another focus of Webler’s research. Calcium can be added to the melt to form calcium-aluminates, converting solid alumina inclusions into liquid droplets, reducing the risk for clogging nozzles. However, adding too much calcium forms undesirable solid calcium sulfide (CaS) inclusions. Using information on the inclusion population, operators can tune how much calcium they add to achieve just the right level. Did calcium sulfide inclusions form? Turn down the calcium. Too much alumina? Add more. The speed at which this analysis is performed can impact the bottom line of the operation both in material costs and process performance.
The promise of computer vision and machine learning in inclusion analysis
Computer vision (CV), an advanced image processing technique that relies on machine learning (ML), is becoming ubiquitous: from facial recognition on smartphones to character analysis for converting old written works to digital texts. Increasingly, CV and ML are being used in materials science. Holm has previously used these techniques to classify carbon nanotubes, predict stress hotspots, and characterize powder feedstocks for 3D-printing. Inclusion analysis, an area rife with images, naturally lends itself towards CV, according to Holm.
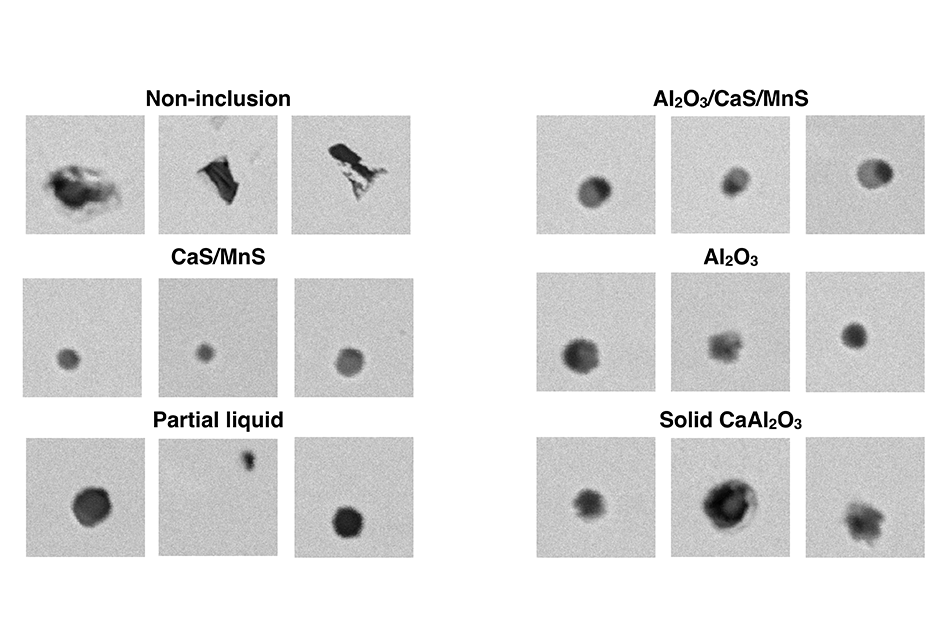
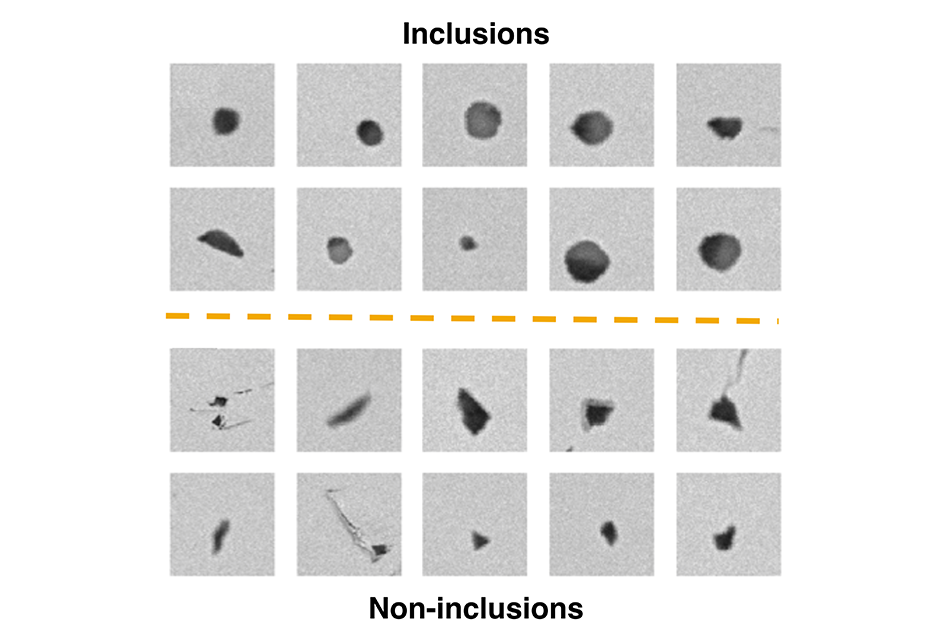

CV may be able to improve how inclusions are analyzed in a handful of ways. First, there are always non-inclusions (e.g. dust, holes, scratches) in SEM images that can be wrongly detected as inclusions (false positives). Even when classified correctly, analyzing false positives is still wasted time for the EDS system, and filtering them out would speed up the process. Further, if CV could determine the chemical composition of inclusions right from SEM images alone, EDS could be eliminated entirely, reducing both equipment and labor costs.
Even more appealing to Webler, though, is the idea that computer vision might elucidate unknown information about inclusions. In other fields, CV has been able to produce insights invisible to human interpretation. An example that Holm points to is a CV system that could “see” traits such as age, gender, and even cardiological risk factors in retinal images. No ophthalmologist had previously uncovered any of those traits by looking at human eyes. By turning CV loose on inclusion images, the team hopes that new insights might be generated, learning through the intricate differences in the images what might be hidden within inclusion populations.
The initial results from Webler’s and Holm’s research are encouraging. From the SEM images they analyzed, they determined with 98% accuracy whether a feature was an inclusion or not. Already, integrating computer vision into the current systems to filter out non-inclusions would likely save time in EDS scans. Differentiating each feature as an inclusion or not took their algorithm 70 milliseconds. Making that same determination using EDS takes more than 14 times as long (roughly 1,000 ms).
Interestingly, Holm said, it was not clear to her by looking at the SEM images why their CV tool classified features in one group or the other. Yet, that it did so with a high degree of accuracy holds promise that more information may still be lurking in the SEM images. The next step, they say, is to “classify inclusions by chemical composition based only on BSE images,” potentially eliminating the need for EDS.
Though he acknowledges that the work is still in its early phases, Webler is optimistic about his team’s approach, and how it could eventually have a positive impact on the industry. “We hear lots and lots about big data, industry 4.0, all of these things, but these techniques are still opaque in a lot of ways,” he said. “But this is one example, at least, where I can see how machine learning techniques could be useful when they are applied in this specific way.”